I’m using jq (think sed/awk/grep for JSON) for a while now. From time to time, people ask me how to do this or that using jq. Most of the questions can be distilled into these two cases:
Show tabular data
Given array of objects, show it in a tabular, human readable format.
Sample jq input: output of aws cloudformation describe-stacks:
{
"Stacks": [
{
"DisableRollback": false,
"StackStatus": "CREATE_COMPLETE",
"Tags": [],
"CreationTime": "2016-05-10T14:16:06.573Z",
"StackName": "CENSORED",
"Description": "CENSORED",
"NotificationARNs": [],
"StackId": "arn:aws:cloudformation:CENSORED",
"Parameters": [
...
]
},
{
...
},
...
}
To show this in a human-readable form you could pipe it to
jq -r '.Stacks[] | "\(.StackName) \(.StackStatus) \(.CreationTime) \(.Tags)"'
Explanation:
-r make the output “raw”. Such output does not include enclosing quotes for each of the strings we are generating.Stacks[] | – for each element in the Stacks array evaluate and output the expression that follows the vertical bar (inexact explanation but it fits this case). When evaluating the expression to the right, the context will be set to one element of the array at a time."..." – a string- Inside the string,
\(.StackName) – The .StackName attribute of current element from the Stacks array.
The output columns will not be visually aligned. I suggest solving the alignment issue by introducing special columns separator character such as % and the using the columns command to visually align the columns. Full solution suggestion:
aws cloudformation describe-stacks | \
jq -r '.Stacks[] | "\(.StackName)%\(.StackStatus)%\(.CreationTime)%\(.Tags)"' | \
column -t -s '%'
Note: I don’t have a good solution for the case when more than one or two tags are present. The output will not look very good.
More AWS-specific JSON formatting is in my .bashrc_aws.
Do something with each object
Given array of objects, iterate over it accessing fields in each array element.
Continuing the example above, assume you want to process each stack somehow.
aws cloudformation describe-stacks | \
jq -rc '.Stacks[]' | while IFS='' read stack;do
name=$(echo "$stack" | jq .StackName)
status=$(echo "$stack" | jq .StackStatus)
echo "+ $name ($status)"
# do your processing here
done
Explanation:
The only new thing here is the -c switch, for “compact”. This causes each resulting JSON representing a stack to be output on one line instead of few lines.
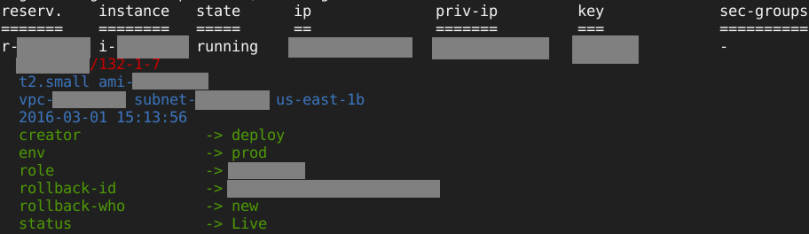
UPDATE: AWS tags handling
I was dealing with instances which had several tags and it was very annoying so using jq man and Google I’ve arrived to this:
aws ec2 describe-instances | jq -r '.Reservations[].Instances[] | "\(.InstanceId)%\(if .Tags and ([.Tags[] | select ( .Key == "Name" )] != []) then .Tags[] | select ( .Key == "Name" ) | .Value else "-" end)%\(.KeyName)%\(if .PublicIpAddress then .PublicIpAddress else "-" end)%\(.LaunchTime)%\(.InstanceType)%\(.State.Name)%\(if .Tags then [.Tags[] | select( .Key != "Name") |"\(.Key)=\(.Value)"] | join(",") else "-" end)"' | sed 's/.000Z//g' | column -t -s '%'
Explanation of the new parts:
if COND_EXPR then VAL1 else VAL2 end construct which returns VAL1 or VAL2 depending on whether COND_EXPR evaluates to true or false. Works as expected.- Why
if .Tags is needed? I want to display something (-) if there are no tags to keep the columns aligned. If you didn’t want do display anything special there… you just had to have this if .Tags anyway. Why? Thank AWS for the convoluted logic around tags! OK, you made tags (which should be a key-value map) a list but then if the list is empty it’s suddenly not a list anymore, it’s a null! I guess this comes from Java developers trying to save some memory… and causing great suffer for the users. The .Tags[] expression fails if .Tags is null.
[...] builds an arrayselect(COND_EXPR) filters the elements so that only elements for which the COND_EXPR evaluates to true are present in it’s output.join("STR") – predictably joins the elements of the array using the given separator STR.
I think that any instances I have that have tags, have the Name tag. I guess you would need to adjust the code above if it’s not the case on your side. If I will have this problem and a fix, I’ll post an update here.
Handling large or complex JSONs
When your JSON is large, sometimes it’s difficult to understand it’s structure. The tool show-struct will show which jq paths exist in the given JSON and summarize which data is present at these paths.
For the example above, the output of aws cloudformation describe-stacks | show_struct.py - is
.Stacks -- (Array of 10 elements)
.Stacks[]
.Stacks[].CreationTime -- 2016-04-18T08:55:34.734Z .. 2016-05-10T14:16:06.573Z (10 unique values)
.Stacks[].Description -- CENSORED1 .. CENSORED2 (7 unique values)
.Stacks[].DisableRollback -- False
.Stacks[].LastUpdatedTime -- 2016-04-24T14:08:22.559Z .. 2016-05-10T10:09:08.779Z (7 unique values)
.Stacks[].NotificationARNs -- (Array of 0 elements)
.Stacks[].Outputs -- (Array of 1 elements)
.Stacks[].Outputs[]
.Stacks[].Outputs[].Description -- URL of the primary instance
.Stacks[].Outputs[].OutputKey -- CENSORED3 .. CENSORED4 (2 unique values)
.Stacks[].Outputs[].OutputValue -- CENSORED5 .. CENSORED6 (2 unique values)
.Stacks[].Parameters -- (Array of 3 elements) .. (Array of 5 elements) (2 unique values)
.Stacks[].Parameters[]
.Stacks[].Parameters[].ParameterKey -- AMI .. VpcId (11 unique values)
.Stacks[].Parameters[].ParameterValue -- .. CENSORED7 (13 unique values)
.Stacks[].StackId -- arn:aws:cloudformation:CENSORED8
.Stacks[].StackName -- CENSORED9 .. CENSORED10 (10 unique values)
.Stacks[].StackStatus -- CREATE_COMPLETE .. UPDATE_COMPLETE (2 unique values)
.Stacks[].Tags -- (Array of 0 elements)
Extras from a friend
AMIs with joined EBS snapshots list and tags
Demonstrates AWS tags values and join for normalization.
Code:
aws ec2 describe-images --owner self --output json | jq -r '.Images[] | "\(if .Tags and ([.Tags[] | select ( .Key == "origin" )] != []) then .Tags[] | select ( .Key == "origin" ) | .Value else "-" end)%\(.ImageId)%\(.Name)%\(if .Tags and ([.Tags[] | select ( .Key == "stamp" )] != []) then .Tags[] | select ( .Key == "stamp" ) | .Value else "-" end)%\(.State)%\(.BlockDeviceMappings | map(select(.Ebs.SnapshotId).Ebs.SnapshotId) | join(",") | if .=="" then "-" else . end)"' | (echo "Source%AMI%Desc%Stamp%State%Snaps"; cat;) | column -s % -t
Output:
Source AMI Desc Stamp State Snaps
serv001 ami-11111111 serv001_20171031054504 1509428704 available snap-1111111111111111
- ami-22222222 prd-db002-20170911 - available snap-2222222222222222
app333 ami-33333333 app333_20171031054504 1509428704 available snap-4444444444444444,snap-7777777777777777
Load-balancers with de-normalized instances
Demonstrates vars for de-normalization
Code:
aws elb describe-load-balancers --output json | jq -r '.LoadBalancerDescriptions[] | . as $l | .Instances[] as $i | [$l.LoadBalancerName] + [$i.InstanceId] | @csv' | sed 's#"##g; s#,#\t#g;' | (echo -e "LB\tInstance"; cat;) | column -t
Output:
LB Instance
wordpress-lb i-11111111
app-lb i-11111111
webapp-prd i-33333333
webapp-prd i-99999999
External links
- StackOverflow – How to convert arbirtrary simple JSON to CSV using jq?
Hope this helps.
Please let me know in comments if there is some another common use case that should be added here.